Unlock your full potential with ComColors training:
innovation for your professional and personal success

100
Made in France

93
satisfaction rate

400
certified trainers
The new ComColors application is now available!
The ComColors app has had a facelift, with a redesigned interface and even more features. Now you can connect to the profiles of people you know, share your colours, and even identify a person’s colours. And that’s not all! You can receive notifications to keep you motivated, manage your relationships or prepare for a meeting.
Videos, podcasts, infographics: you can access the entire ComColors model from your smartphone.
Don’t change a thing, you’re great!

In the midst of all the injunctions to change that we receive on a daily basis, we’ve taken the gamble that you already have everything in you to succeed. The real challenge is to discover your true personality, beyond the masks and external demands. Accepting yourself as you are opens the door to your natural strengths that you can draw on to succeed.
ComColors reveals your authentic way of working. You’ll then be on the road to a profound transformation of your environment and your expectations to make them correspond to you, quite simply.
Find out more about the ComColors approach
Understanding and applying the ComColors model
ComColors books

To understand everything about the model according to your profile and your needs, at your own pace
ComColors profile + individual debriefing

To discover your ComColors personality profile and your natural strengths
2-day ComColors training course + full personality profile

To learn how to apply the model in all everyday situations
ComColors certification training

To join the network of over 400 professionals
Communication, management, well-being at work

Start the profound transformation of your teams with the ComColors model
Self-knowledge, career choice, teamwork

Give your students the tools they need to succeed academically and professionally
A more harmonious and productive environment, both personally and professionally
Personality types offer a fascinating insight into human complexity, enabling a deeper and more nuanced understanding of oneself and others. By identifying the dominant characteristics of each type, they help to decipher motivations, preferences and behavioural reactions in a coherent way. They open a window onto how different personality types process information and interact with their environment. And that’s the key to effective communication.
Personality type models also offer advantages in the professional sphere. Understanding and using them enables everyone to align themselves with roles that match their natural strengths. They also make it easier to build balanced teams by drawing on the varied skills and perspectives of each type.
Discover ComColors solutions for your company

An innovative approach and a tried and tested model
For nearly 20 years, ComColors has been working to give everyone a better understanding of themselves. We have developed innovative tools to help you make the model your own and put it into practice in all everyday situations.
Our priority is to make the model and its supports accessible and easy to use, so that discovering your personality is a fun, straightforward and caring experience. We value your feedback so that we can constantly improve the way we explain the theory behind the ComColors model. What’s more, we create daily content on social media to make discovering your profile as entertaining as possible.
Explore ComColors' digital tools
A valuable and playful model
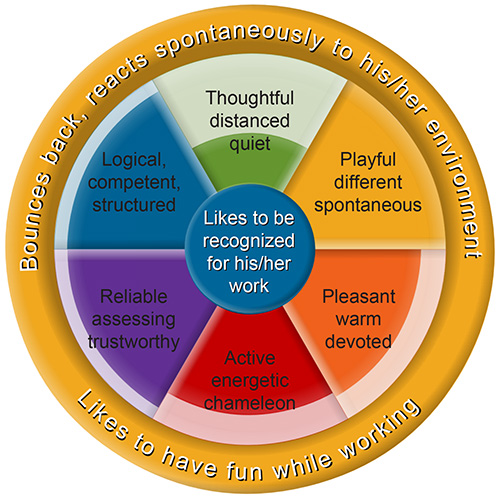
The ComColors model has defined 6 personality types identified by colours. Each colour represents a specific way of functioning that includes behaviours measured by science: motivation, perception filter (the way you see the world), and behaviour under stress.
Your ComColors personality profile contains a wealth of information about how you function. In addition to your dominant and secondary colours, you will discover :
- your sources of motivation ;
- your behaviours under stress;
- the way you perceive the world;
- your favourable environment ;
- …
Discover the theory behind the ComColors model
Dernière mise à jour le 6 February 2024